Team Teach - Big Ideas
All about the big ideas of CSP learned through the team teaches. All are linked with associated information. I have used this to study and allows for easy access to all of the needed information.

Beneficial Effects Of Computing
- Medical advancements (e.g., AI diagnostics)
- Enhanced business efficiency via automation
- Global collaboration tools for creators
- Environmental monitoring systems
Positive Impacts on Society
Computing innovations revolutionize healthcare, business, and creativity. Tools like AI, cloud platforms, and data analytics enable faster problem-solving, improved accessibility, and sustainable solutions.

Harmful Effects of Computing
- Privacy erosion through data mining
- Job displacement due to automation
- Cyberbullying and mental health risks
- Environmental costs of e-waste
Unintended Consequences
While technology advances society, it also introduces risks like dependency, inequality, and ethical dilemmas. Issues such as algorithmic bias, surveillance, and resource overconsumption require mitigation.

Digital Divide
- Browser-Based Tools (Replit, Jupyter Notebooks) for low-spec devices
- Linux for affordability (Chromebooks/old hardware)
- WSL on Windows to simulate Linux without costly hardware
- Open-source alternatives (e.g., LibreOffice, VS Code)
Inclusive Development Setup
Developers in underserved communities often rely on low-cost devices. Browser-based tools, Linux distributions, and cross-platform workflows ensure access to JavaScript, Python, and Java development regardless of hardware limitations. Open-source ecosystems reduce costs and foster global collaboration.

Computer Bias
- Default OS assumptions: WSL for Windows, MacOS for Apple, Linux/KASM for Chromebook
- Tool compatibility gaps for underrepresented systems
- Testing disparities (e.g., facial recognition bias in hardware)
- Reinforced stereotypes (e.g., 'developer-friendly' OS)
Recognizing Exclusion in Tools
Default OS and toolchains often reflect developer assumptions, excluding users with limited resources or accessibility needs. For example, tools optimized for Linux may fail on other systems (like the HP camera's racial bias in untested environments). Inclusive development requires testing across diverse setups and documenting edge cases.

Crowdsourcing
- Distributed problem-solving (e.g., Foldit's HIV enzyme breakthrough)
- Collective intelligence for data aggregation (Wikipedia, AI training)
- Gamification of complex tasks (Foldit players vs. AI)
- Crowd-driven innovation (Kickstarter, Spotify playlists)
Collaborative Problem-Solving
Crowdsourcing leverages global participation to solve challenges faster and more inclusively. Examples like Foldit (gamers solving HIV enzyme structures) and Wikipedia (community-edited knowledge) demonstrate how breaking tasks into smaller, distributed pieces empowers diverse contributors. Crowdfunding, crowd voting, and open collaboration tools democratize innovation, aligning with Big Idea 5's focus on computing's societal impact.

Legal & Ethical Concerns
- Copyrights: Protect code, art, and digital content ownership
- Patents & Trademarks: Safeguard inventions and branding
- Plagiarism Risks: Unauthorized code reuse and AI-generated content
- Prevention: Licensing, DRM, watermarking, and proper attribution
Ethical Development Practices
Developers must navigate intellectual property laws, copyright protections, and ethical coding standards. Unauthorized use of code, AI-generated content, or digital assets can lead to legal disputes (e.g., lawsuits for proprietary code violations). Strategies like licensing agreements, digital rights management (DRM), and proper citation align with ethical practices. Understanding fair use, public domain guidelines, and plagiarism consequences ensures compliance while fostering innovation.
Safe Computing
- Multi-Factor Authentication (MFA) for account security
- Encryption (SSL/TLS, Certbot) for data protection
- Phishing & Malware Prevention (rogue access points, keylogging)
- Antivirus & Secure Network Practices (HTTPS, VPNs)
- PII Protection: Minimizing data collection risks
Security Best Practices
Developers and users must prioritize security to safeguard personal data (PII) and systems. Multi-factor authentication, encryption tools like Certbot, and awareness of phishing/malware threats prevent unauthorized access. Secure coding practices include avoiding untrusted freeware, validating certificate authorities, and adhering to regulations like GDPR. Understanding risks like rogue access points or data interception ensures ethical and compliant computing.
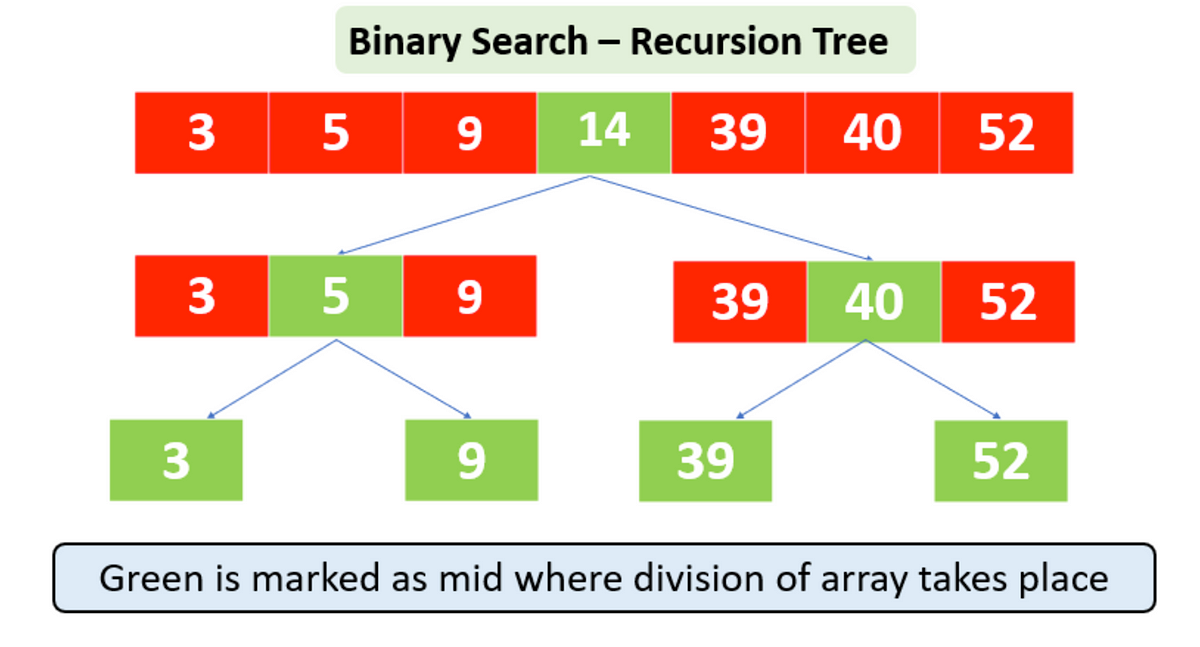
Binary Search Algorithm
- O(log n) time complexity for efficient searching
- Requires sorted data (ascending/descending order)
- Divide-and-conquer approach halves search space
- Edge cases: empty lists, duplicates, integer overflow
- Outperforms linear search (O(n)) for large datasets
Efficient Data Retrieval
Binary search locates targets in sorted lists by repeatedly dividing the search interval. Its O(log n) efficiency makes it ideal for large datasets (e.g., databases, dictionaries). The Python implementation uses `low` and `high` pointers to narrow down the target, while edge cases like duplicates or overflow are handled via mid calculation adjustments. Applications include AI pathfinding, network routing, and Python's `bisect` module.
Filtering Algorithms
- Condition-based extraction (e.g., even numbers, voting age)
- List comprehensions for concise implementation
- Linear time complexity (O(n)) for scalable performance
- Handling heterogeneous data types (integers, strings, booleans)
- Applications: Data cleaning, analytics, and preprocessing
Efficient Data Extraction
Filtering algorithms selectively extract elements from lists using conditions like age thresholds or parity checks. Python's list comprehensions (e.g., `[num for num in numbers if num % 2 == 0]`) enable concise, readable implementations. With O(n) time complexity, these algorithms efficiently process large datasets for tasks such as eligibility checks or data sanitization. Mastery of filtering ensures robust data manipulation in analytics, machine learning, and application development.

Random Algorithms
- Applications: Cryptography, AI (random forests), Monte Carlo simulations
- Python `random` module (e.g., choice(), shuffle())
- Stochastic optimization (simulated annealing, genetic algorithms)
- Fairness in decision-making (lotteries, load balancing)
- College Board Big Idea 3.15 (Random Values)
Stochastic Solutions
Random algorithms use controlled randomness to solve problems efficiently. Examples include Python's `random.choice()` for activity selection, cryptographic key generation, and Monte Carlo simulations in finance/biology. These algorithms ensure fairness (e.g., randomized clinical trials) and handle uncertainty, aligning with College Board's focus on Big Idea 3.15. Implementations range from joke randomizers to neural network training via stochastic gradient descent.

Simulations
- Applications: Engineering (ANSYS), healthcare (surgical VR), climate modeling
- Risk/Cost Reduction: Virtual prototypes, disaster planning
- Stochastic Models: Dice rolls, Rock-Paper-Scissors, Monte Carlo methods
- College Board Big Idea 3.16 (Simulations)
- Tools: MATLAB, SolidWorks, physics engines
Modeling Real-World Systems
Simulations replicate complex systems (e.g., disease spread, flight dynamics) to predict outcomes without real-world risks. Examples include NASA mission testing, epidemiological models, and financial risk analysis. Python scripts like dice rolls (`random.randint()`) or Rock-Paper-Scissors games demonstrate stochastic behavior, while tools like ANSYS optimize engineering designs. Aligns with College Board’s focus on iterative testing and scenario analysis.
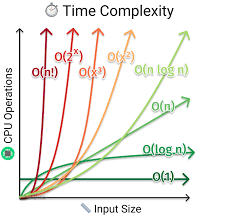
Big O Notation
- O(1): Constant Time (e.g., array access)
- O(log n): Logarithmic Time (e.g., binary search)
- O(n): Linear Time (e.g., single-pass loops)
- O(n log n): Linearithmic Time (e.g., merge sort, quicksort)
- O(n²), O(2ⁿ), O(n!): Quadratic, Exponential, Factorial complexities
Algorithm Efficiency
Big O notation characterizes how an algorithm’s time or space requirements scale with input size. Constant operations (O(1)) stay fixed, logarithmic (O(log n)) arises in divide-and-conquer, linear (O(n)) from single loops, and linearithmic (O(n log n)) in efficient sorts. Higher-order complexities—quadratic, exponential, factorial—grow rapidly, guiding developers toward scalable designs and performant code.

Graphs & Heuristics
- Nodes & Edges: vertices and connections in a graph
- Graph Types: directed/undirected, weighted/unweighted
- Applications: social networks, routing, recommendation systems
- Heuristic Search: Greedy algorithms and A* for path-finding
- NP-Hard Challenges: Traveling Salesman Problem and exponential route growth
Graph Theory & Search Strategies
Graph theory models relationships via nodes (vertices) and edges (connections), supporting directed vs. undirected and weighted vs. unweighted forms. Heuristic methods—such as Greedy algorithms and A* search—use rules of thumb to find efficient approximate solutions. These concepts power real-world applications from social network analysis and GPS routing to tackling NP-hard problems like the Traveling Salesman Problem, where exact solutions become infeasible at scale.
AP CSP Ultimate Guide Summary
Big Idea 1: Creative Development (13%)
- Collaboration Benefits:
- Exchange ideas, multiple perspectives, clarify misunderstandings, reduce bias.
- Occurs in planning, testing, or design phases.
- Pair Programming: Two programmers work on the same algorithm together.
- Key Concepts:
- User Interface (UI): Inputs/outputs for user interaction.
- Variables: Use camelCase (e.g.,
stopButton). - Program vs. Code Segment: Program = full instructions; code segment = part of a program.
- Program Types:
- Event-Driven: Responds to user/system events (e.g., button clicks).
- Sequential: Executes code in order.
- Development Processes:
- Iterative: Prototype → test → refine.
- Incremental: Build small pieces, integrate after testing.
- Documentation:
- Comments (e.g.,
// This button changes the screen). - Libraries/APIs: Pre-built functions with parameters and return values.
- Comments (e.g.,
- Errors:
- Syntax: Spelling/punctuation mistakes (e.g., missing semicolon).
- Logic: Incorrect algorithm (e.g., overlapping conditions in
IFstatements). - Runtime: Crashes during execution (e.g., division by zero).
- Overflow: Number exceeds storage range.
Big Idea 2: Data (22%)
- Data Basics:
- Binary/Decimal: Bits (0/1), bytes (8 bits = 256 combinations).
- Analog vs. Digital: Analog = continuous (e.g., clock time); digital = discrete samples.
- Data Abstraction: Simplify data by removing unnecessary details.
- Compression:
- Lossless: Exact reconstruction (e.g., run-length encoding:
5F6I7V4E). - Lossy: Approximate reconstruction (e.g., JPEG/MP3).
- Lossless: Exact reconstruction (e.g., run-length encoding:
- Metadata: Data about data (e.g., file creation date). Does not alter primary data.
- Data Analysis:
- Correlation ≠ Causation.
- Cleaning: Handle incomplete/invalid data.
- Visualization: Bar charts (categories), scatter plots (correlation), line graphs (trends).
- Big Data Challenges: Requires parallel systems, may contain bias.
Big Idea 3: Algorithms & Programming (35%)
- Variables:
- Global: Accessible everywhere (declared outside events).
- Local: Limited scope (declared inside events).
- Data Types:
- Strings: Use
+for concatenation,\nfor new lines. - Lists/Arrays: Ordered sequences (e.g.,
foodList = ["fish", "chicken"]). - Boolean:
true/falsefor conditionals.
- Strings: Use
- Operators:
&&(AND),||(OR),!(NOT).
- Conditionals:
- Nested
IF-ELSElogic (e.g., grading system).
- Nested
- Loops:
- For: Fixed iterations.
- While: Runs until condition fails (risk of infinite loops).
- Lists Operations:
- Access/modify elements by index (starts at 1 in pseudocode).
- Insert, append, remove, length.
- Search Algorithms:
- Linear: Check each element.
- Binary: Split sorted list (faster, requires sorted data).
- Procedures:
- Reusable code blocks with parameters (e.g.,
summing_machine()).
- Reusable code blocks with parameters (e.g.,
- Algorithm Efficiency:
- Reasonable: Polynomial time (e.g.,
n²). - Unreasonable: Exponential/factorial time (e.g.,
2ⁿ).
- Reasonable: Polynomial time (e.g.,
- Simulations: Abstract real-world systems (e.g., traffic models).
Big Idea 4: Computer Systems & Networks (15%)
- Internet Basics:
- Protocols: TCP/IP (reliable, ordered packets), UDP (fast, no error-checking).
- IPv4 vs. IPv6: IPv6 uses hexadecimal for larger address space.
- Packets: Data chunks with headers for routing.
- Fault Tolerance:
- Redundancy: Backup components to prevent system failure.
- Computing Types:
- Parallel: Multiple processors (faster execution).
- Distributed: Multiple devices (solve large-scale problems).
- Execution Time:
- Sequential: Sum of all steps.
- Parallel: Longest step among divided tasks.
- Speedup: Sequential time ÷ Parallel time.
Big Idea 5: Impact of Computing (26%)
- Digital Divide: Unequal access to tech due to demographics, geography, income.
- Bias in Computing:
- Training data bias (e.g., facial recognition inaccuracies).
- Mitigation: Diverse datasets, algorithmic audits.
- Legal/Ethical:
- Copyright: Protect intellectual property.
- Creative Commons/Open Source: Free-to-use/modify works.
- Safe Computing:
- Malware: Viruses (user-activated), worms (self-replicating).
- Phishing/Keylogging: Steal data via deception.
- Encryption: Symmetric (one key) vs. asymmetric (public/private keys).
- Authentication:
- Passwords, MFA (knowledge/possession/biometrics).
Exam Tips
- Code Review: Trace variables line-by-line.
- Time Management: Skip hard questions, revisit later.
- FRQs: Be specific, avoid generic answers.
- Vocab: Know terms (e.g., metadata, TCP/IP).
- Pseudocode: List indexes start at 1.
Collaboration Benefits
List three benefits of collaboration in the software development process and identify during which phases collaboration is most valuable.
Pair Programming
What is pair programming and how does it improve code quality and team communication?
Iterative vs. Incremental Development
Compare iterative and incremental development processes. Give an example of when you might use each approach.
User Interface and Documentation
Explain the role of user interface design and inline documentation (comments) in making code maintainable and user-friendly.
Types of Programming Errors
Define syntax, logic, runtime, and overflow errors. Provide an example scenario for each type.
Data Abstraction
What is data abstraction and why is it important when working with large or complex datasets?
Lossless vs. Lossy Compression
Describe the difference between lossless and lossy compression. Give one real-world example of each.
Metadata
What is metadata and how does it support data management without altering the primary data?
Correlation vs. Causation
Why does 'correlation does not imply causation' matter in data analysis? Provide an illustrative example.
Global vs. Local Variables
Differentiate between global and local variables and discuss a scenario where each is appropriately used.
Linear vs. Binary Search
Compare linear and binary search algorithms in terms of process, requirements, and efficiency.
Algorithm Efficiency
What makes an algorithm 'reasonable' (polynomial time) versus 'unreasonable' (exponential/factorial time)? Provide one example of each.
TCP/IP vs. UDP
Explain the differences between TCP/IP and UDP protocols, including typical use cases for each.
Parallel vs. Distributed Computing
Describe parallel and distributed computing architectures and give an example problem suited to each.
Digital Divide
What is the digital divide and what strategies can be used to mitigate its impact on under-served communities?
Symmetric vs. Asymmetric Encryption
Compare symmetric and asymmetric encryption methods, including key management and typical applications.
Multi-Factor Authentication
List and explain the three categories of authentication factors used in secure systems.